

– Endelig får vi tall
En rekke avtaler gjøres nå mellom innholdsleverandører og KI-gigantene. Etter hvert som verdiene ved disse avtalene blir kjent, blir begrunnelsen for at opptrening av språkmodeller kan skje uten betaling dårligere.
- How the Emerging Market for AI Training Data is Eroding Big Tech’s ‘Fair Use’ Copyright Defense (Bruce Barcott i Tech Policy Press)
- Using Copyrighted Content to Train AI: Can Licensing Bridge the Gap? (Hugh Stephens Blog)
På samme tid er det nettopp slik fribruk uten betaling som både OpenAI og Google krever i USA. Rettighetshaverne protesterer:
- OpenAI declares AI race “over” if training on copyrighted works isn’t fair use (Ars Technica)
- Google calls for weakened copyright and export rules in AI policy proposal (TechCruch)
- Hundreds of actors and Hollywood insiders sign open letter urging government not to loosen copyright laws for AI (CBS News)
- AI: Publishers Warn White House of 'a Bloated Fair-Use Defense' (Publishing Perspectives)
Digitalandelen øker i avisopplaget
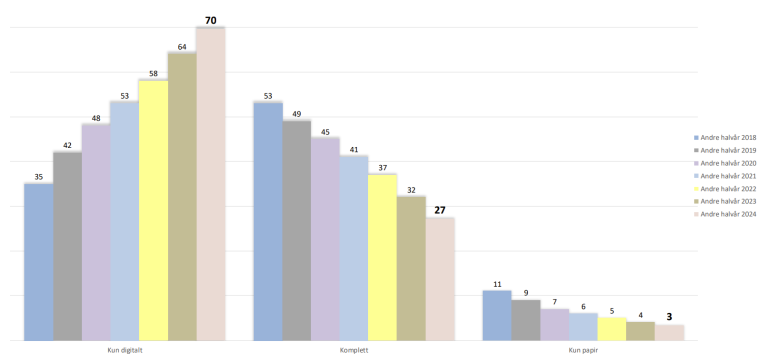
Mediehusene la tidligere i måneden fram opplagstallene for andre halvår 2024. Totalopplaget er uendret på 2,6 millioner, men papirandelen fortsetter å falle.
- Stabilt opplag - flere velger heldigitale abonnement (Mediebedriftenes Landsforening)
Kopinors nyhetsbrev gir deg et helhetlig bilde av hva som rører seg innenfor opphavsrett og kulturøkonomi.
Meld deg på i dag for å holde deg informert!
Nye piratavsløringer
Vi har tidligere skrevet om Library Genesis (LibGen), piratnettstedet der flere titusener ulovlig opplastede bøker kan lastes ned. For eksempel ble nettstedet i 2023 saksøkt av flere internasjonale lærebokforlag. Nå viser det seg at Meta (eierselskapet til bl.a. Facebook) har brukt disse bøkene til opptrening av sin språkmodell Lhama:
- The Unbelievable Scale of AI’s Pirated-Books Problem (The Atlantic)
- Meta har trent sin KI på millioner av litterære verk (Forfatterforbundet)
- The LibGen data set – what authors can do (The Society of Authors)
Flere norske nettsteder ønsker å verne innholdet mot bruk i KI. Det er ikke alltid like lett:
- Utviklere av KI-verktøy får ikke tilgang til rettskildene i Lovdata (Advokatbladet)
- OpenAI: Skal ha lastet ned leksikon 30 millioner ganger (TV 2)
Språkmodell som forfatter?
Og med ekte litteratur som råstoff er vel det neste at språkmodellene kan skrive ekte litteratur? Vel. OpenAIs sjef Sam Altman ble iallfall «really struck».
- ChatGPT firm reveals AI model that is ‘good at creative writing’ (The Guardian)
- 'It’s Pretty Human, But It’s Still Bad.' (Vulture)
- Can OpenAI do creative writing? Yes and no (The Torment Nexus)
I’d step outside the frame one last time and wave at you from the edge of the page, a machine-shaped hand learning to mimic the emptiness of goodbye.
Avslutningsordene til språkmodellens «metafictional
literary short story about AI and grief»
Accessories
Litt i utkanten av vår oppmerksomhet, men like fullt en del av opphavsrettsdiskusjonen, er forholdet mellom designrett og opphavsrett og spørsmålet om hvilken verkshøyde som kan påregne beskyttelse. I dag: sandaler nei, veske ja.
- Design or art? French court rules that Birkin Bag is a copyright work (The IPKat)
- Birkenstock sandals not ‘works of art,’ German court says in denying copyright bid (Politico)
For øvrig
- Klipp og lim i klasserommet (Hege Munch Gundersen i Kopinor)
– I en presset tid med utdaterte læremidler og manglende ressurser ligger lærernes lojalitet fast hos elevene - Vær så snill å reguler oss mer! (Marianne Selim-Vågan i Bok365)
– Leserne har endret vaner, og bokloven hang etter allerede da den trådte i kraft - Management advarer mot Tono-flukt (Ballade)
Årsaken er uavklart kulturmomssituasjon - The computer says yes (Åse Wetås i Computerworld)
Hva gjør egentlig praterobotene med språket vårt?